Memory¶
Memory Technology¶
-
SRAM: Static Random Access Memory 静态随机内存访问存储器
- 它只有一个访问端口,具备读和写的能力
- 访问任何数据所需的时间是固定的
- 由于无需刷新 (refresh),因此访问时间接近于处理器的周期时间
- 应用:高速缓存 cache
-
DRAM: Dynamic Random Access Memory 动态随机内存访问存储器
- 1 位数据以电荷的形式被存储在 1 个电容中
- 电容会随着时间逐渐泄漏电荷,因此需要定期刷新 (refresh) 以保持数据
- 访问时间取决于电容的刷新时间
- 应用:主存
-
Flash
- Disk
Intro¶
局部性locality原理:
-
Temporal Locality: 时间局部性
最近访问过的item,大概率会被再次访问(loop)
-
Spacial Locality: 空间局部性
最近访问过的item附近的item,大概率会被访问(array)
离CPU越近的memory,访问速度越快,容量越小,价格越贵
Important Items
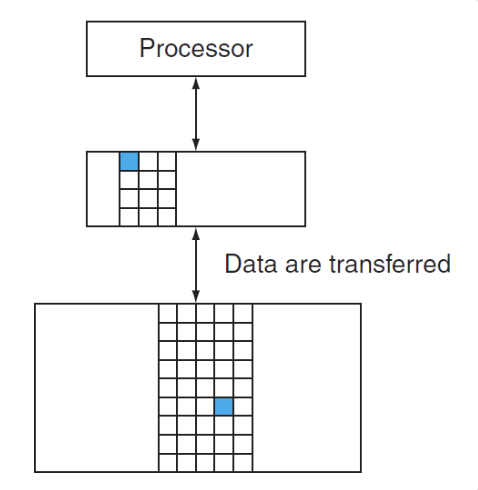
- Block(line): 操作单元,就如上图从内存搬运到cache的单位
-
Hit: 命中,我们所需要访问的数据处于upper level(这里就是说蓝色的方块到cache中了)
- Hit Ratio:命中率=命中次数/访问次数,计算机中通常程序指令的命中率在90%以上,数据相对来说低一些
- Hit Time:访问upper level数据的时间,其中包括了判断数据是否命中的时间
-
Miss:所需访问的数据没有被拉到upper level中
-
措施:copy一个block到upper level中
- Time taken:搬运的时间成为miss penalty
- Miss Ratio:= 1-Hit Ratio
- Miss Penalty:替换upper level中block的时间,加上将block送到processor的时间
-
这里我们说的upper level就是说cache,但实际上在计算机中可以是由内存到cache,也可以是硬盘到内存
常见的memory hierarchy:
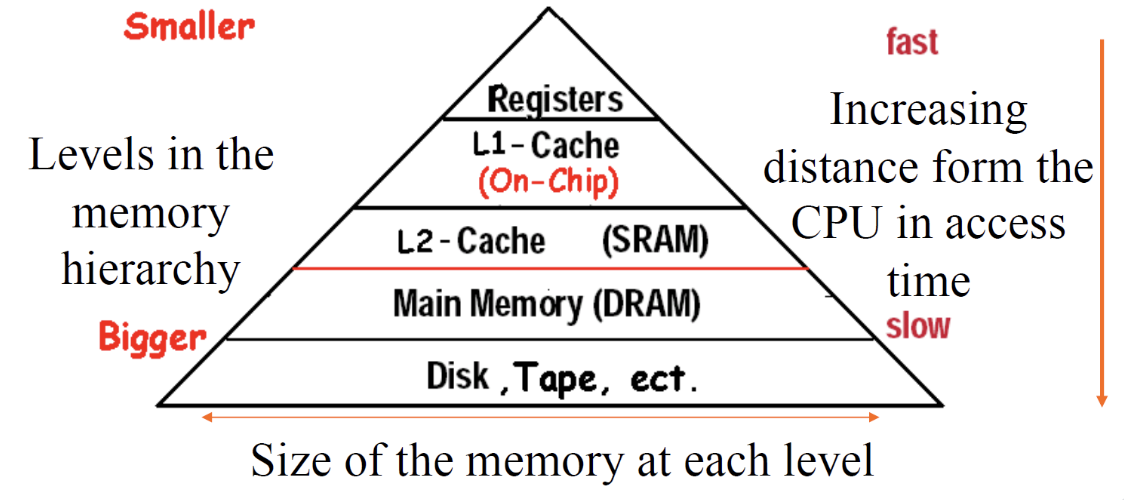
接下来我们要解决两个方面的问题:
-
The basics of Cache - speed
SRAM and DRAM
-
Virtual Memory - size
DRAM and Disk
Cache¶
内存中的每一个数据在cache中都有一个唯一的地址对应,这意味着lower level中的很多item在upper level中共享同一个地址
需要解决两个问题:
- 如何确定一个数据是否在cache中
- 如何找到它
Cache Mapping¶
-
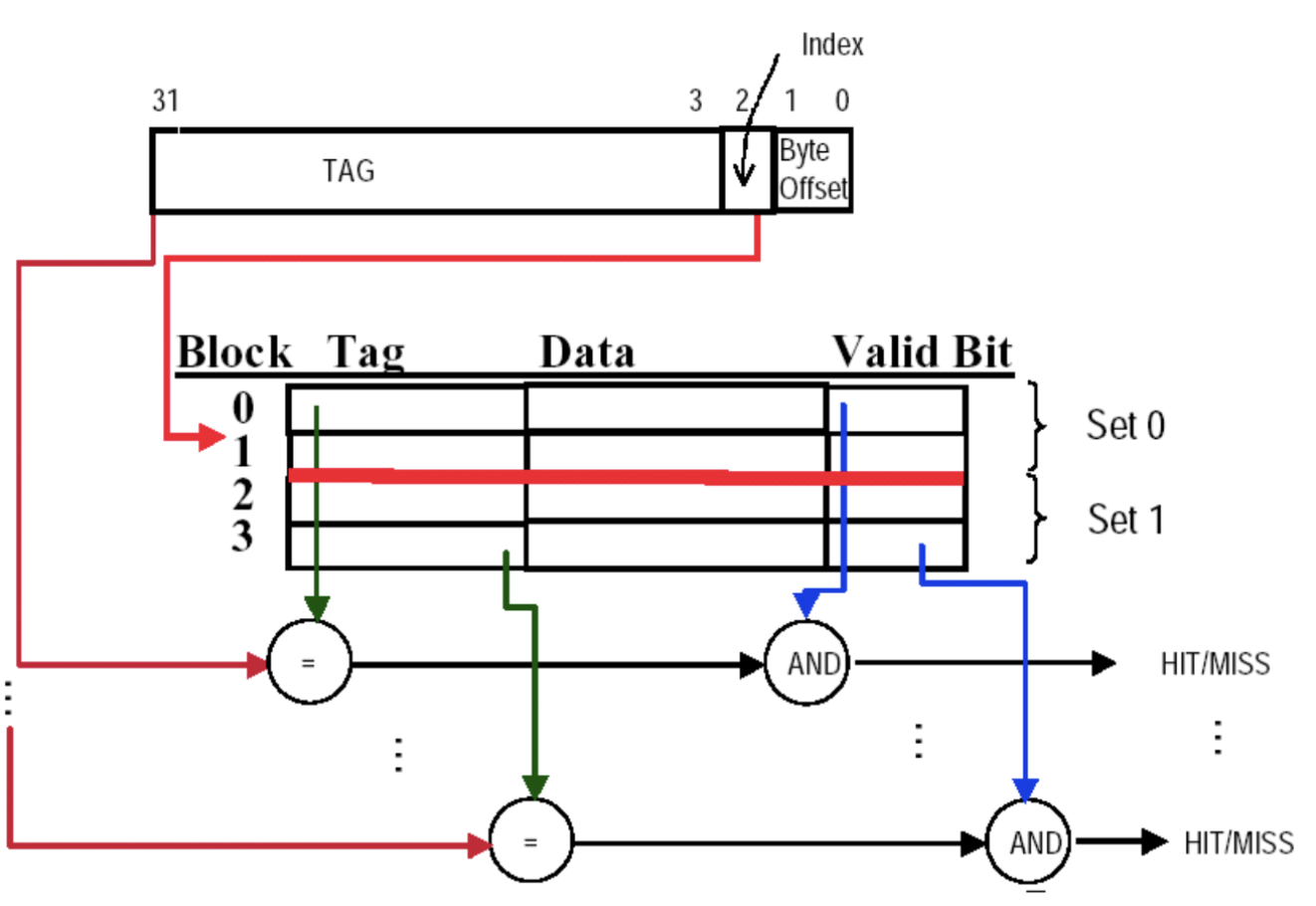
Direct Mapping
- 方法:取模,将内存地址的低位作为cache的index,如图就是取低3位作为index
- tag:在进行存储时,我们放进的位置是block的低位,但是很多个block都在一个位置,因此我们需要存储数据的完整地址,所以需要将内存地址的高位作为tag
- Valid bit:用于判断cache中是否存在数据
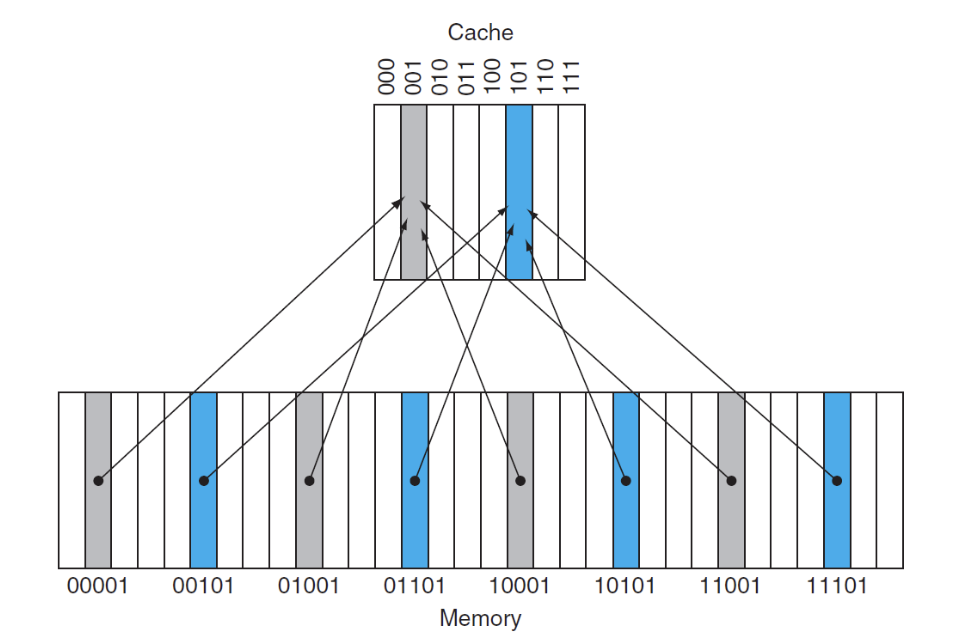
下面这张图给出了内存地址与高速缓存中的地址的映射关系:
- 这里地址是64位,
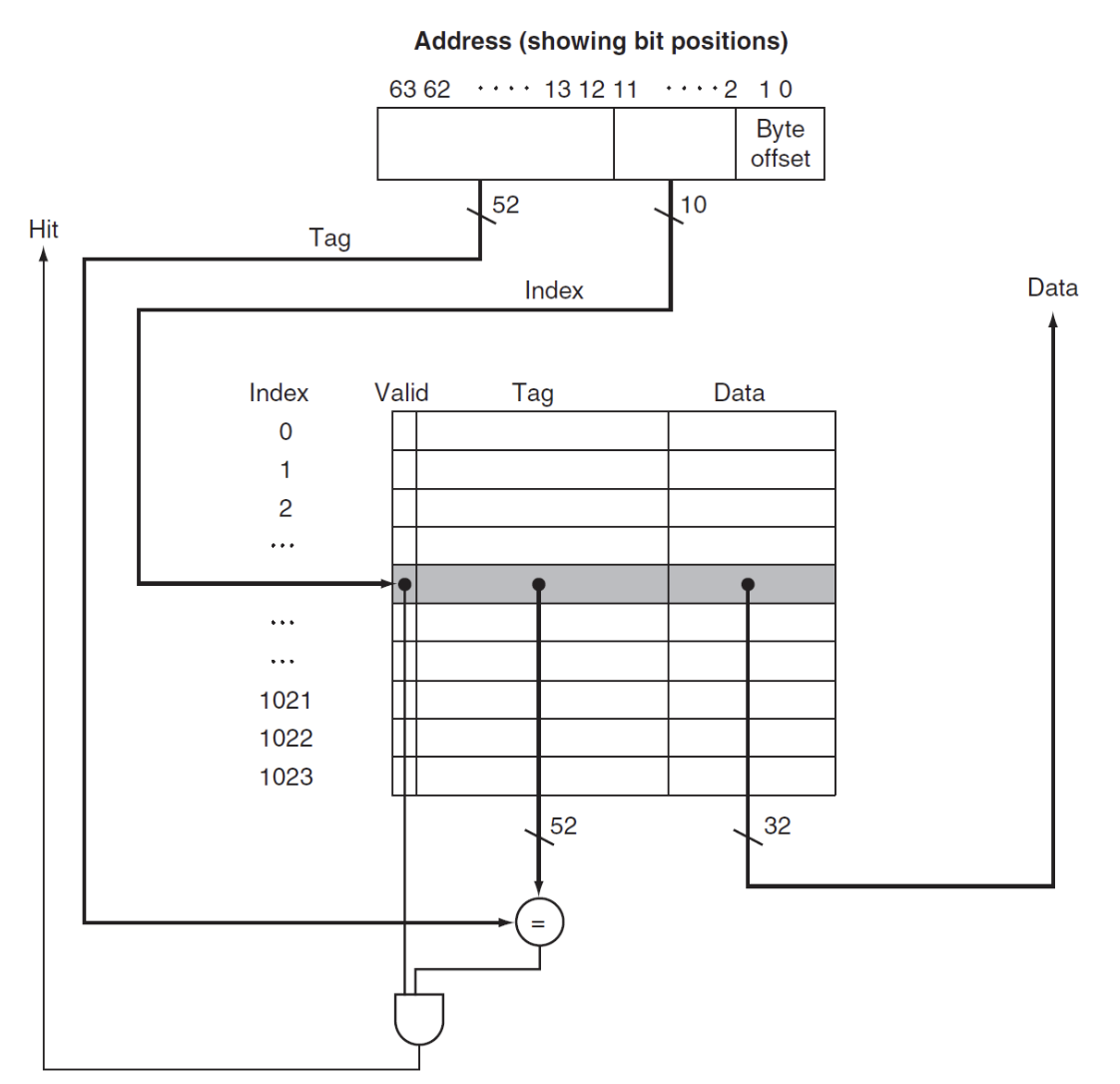
-
Byte offset:由block size决定
- 当size为1 word时,offset有两位
- 当size为4 word时,offset有四位
-
后面有补充:
\[ \text{Byte Offset} = \log_2(\text{# bytes per block}) \]
-
Index:由cache size决定,也就是cache中的block数量
- 当cache size是8个block时,index有3位
-
Tag:总的地址长度减去index和offset后得到的,存放在cache中用来判断是否命中

注意
在这里我只给出了计算方法,实际上如果理解了每个部分的作用,那么就可以直接从内存地址中得到index和tag,但是我对offset的理解不太到位,马德上课说offset要直接砍掉的(?)所以我选择记住()…… 好吧他后来讲明白了,byte offset就是一个block中byte的个数决定的
这里有一个例题:对一个8block的cache进行访问,我们得到的内存地址已经直接砍掉了offset
例子
给出完整的访问过程,我们逐步对每个状态进行分析:
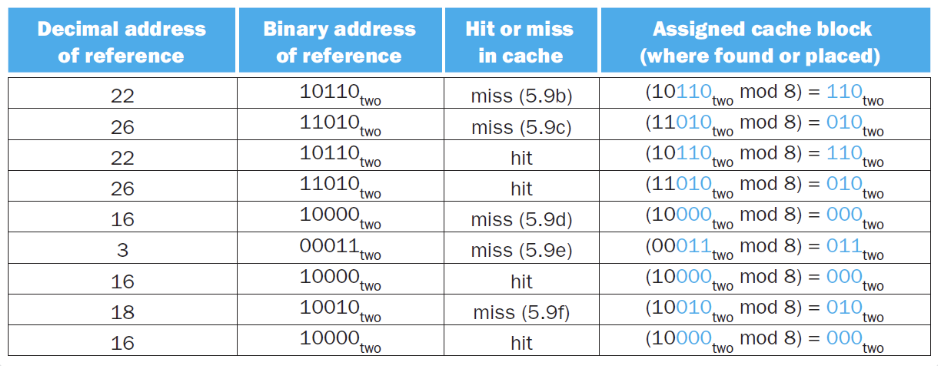
接下来就是每一步的状态,我们可以分析得出每一步是否hit
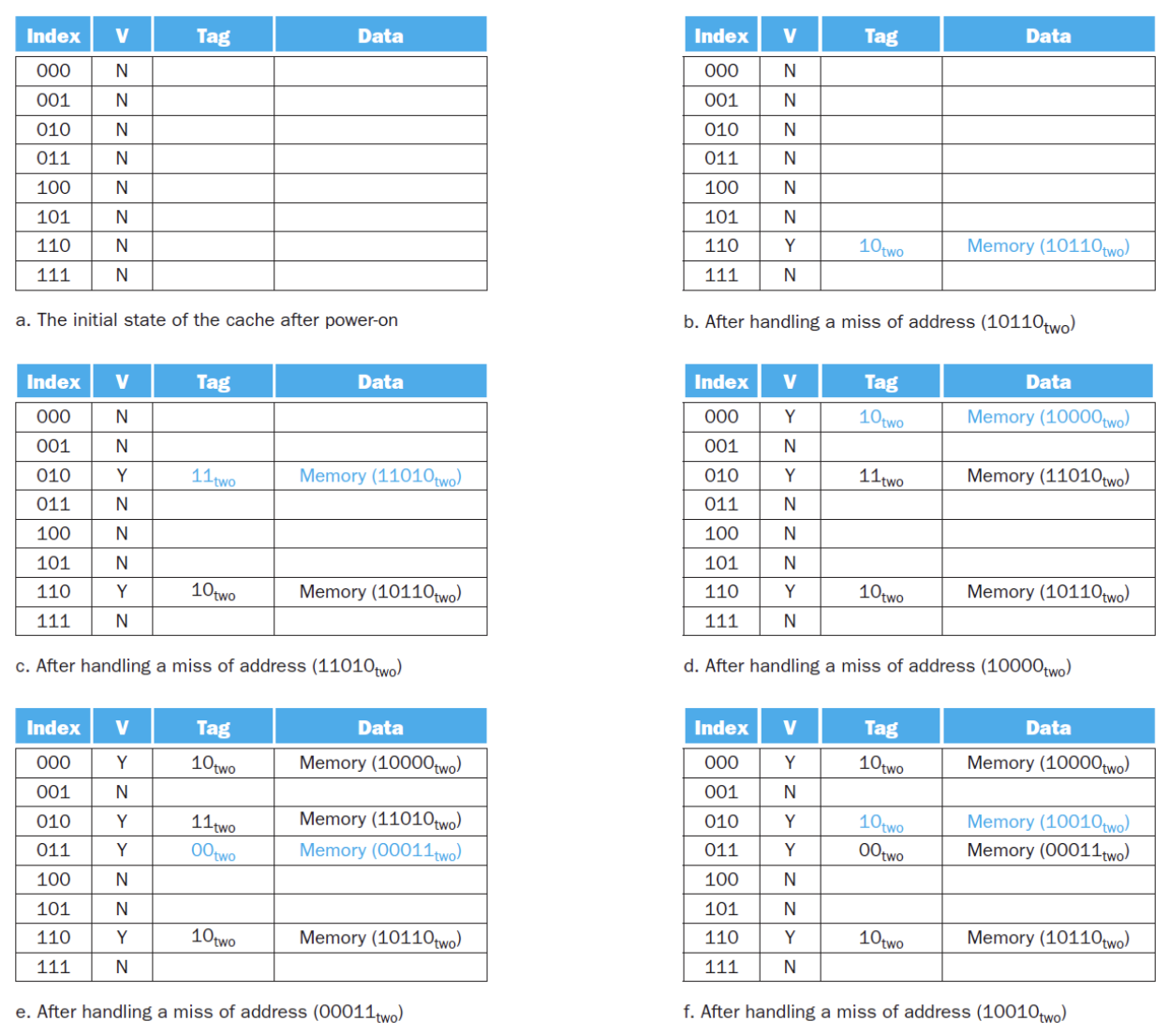
大体的流程就是:
- 读取CPU给出的目标内存地址
- 通过index找到cache中的block
-
判断内存地址的tag是否与cache中block的tag匹配
- 如果匹配,则hit
- 如果不匹配,则miss,同时在默认策略下,将所需要的tag的那个内存替换到cache中
-
对于没有写过的block,Valid bit为0,只要写过,Valid bit就为1
-
最后取数据时,根据offset,从cache对应block中的data位置取出对应的
例题
How many total bits are required for a direct-mapped cache with 16KB of data and 4-word blocks, assuming that the address is 32 bits long?
- 16 KB = 4K word = \(2^{12}\) words
- 4 word block = \(2^2\) word block
- number of blocks = \(2^{12}\) words / \(2^2\) word per block = \(2^{10}\) blocks
- data bits = 4 word * 32 bits = 128 bits
- tag bits = 32 bits - 10 bits - 4 offset = 18 bits
- valid bits = 1 bit
- total bits = \(2^{10}\)(18 + 128 + 1) = 147 Kbits
给定一个高速缓存,它有 64 block,每块空间为 16 bytes,请问内存byte address为 1200 的数据所映射到的块的编号为多少?
- 1200 / 16 = 75 得到block address
- 75 % 64 = 11 得到index
所以,内存byte address为 1200 的数据所映射到的块的编号为 11
假设一个高速缓存有 4096 个高速缓存块,每个块的大小为 4 字,并且内存采用 64 位地址。请计算在直接映射、两路组相联、四路组相联以及全相联的置放方案下高速缓存的组数以及总的标签位数。
- 每个块大小是4个word,offset = 4
-
直接映射
- 直接映射的组数就是cache的block数量,4096
- index = \(\log_2(4096) = 12\)
- tag = 64 - 12 - 4 = 48
- 总的标签位数 = 4096 * 48 = 192Kb
-
两路组相联
- 组数 = 4096 / 2 = 2048
- index = \(\log_2(2048) = 11\)
- tag = 64 - 11 - 4 = 49
- 总的标签位数 = 4096 * 49 = 196Kb
-
四路组相联
- 4096 * (64 - 10 - 4) = 4096 * 50 = 205Kb
-
全相联
- 组数 = 1
- index = 0
- tag = 64 - 0 - 4 = 60
- 总的标签位数 = 4096 * 60 = 240Kb
Handling Cache Miss¶
当发生miss时,整个系统的操作:
-
Read miss:
- 将源地址送进内存(current_PC-4,也就是发生miss的指令的地址)
- 让main memory做一次read
- 将main memory取回的数据写到cache entry中(entry就是Valid bit,tag,data一整个完整组成)
- Restart 指令流程,相当于重新执行fetch操作
-
Write hit:有两种策略写回数据
- Write through:将数据同时写入memory和cache
- Write back:只写入cache,之后再写入memory
Deep Cache Concepts¶
在这一节,我们将深入讨论cache的相关问题,一共有四个问题:
核心问题
-
Block Placement
在哪里替换block?
-
Block Identification
怎样找到一个block?
-
Block Replacement
怎样替换一个block?
-
Write Strategy
怎样写入数据?
Block Placement¶
-
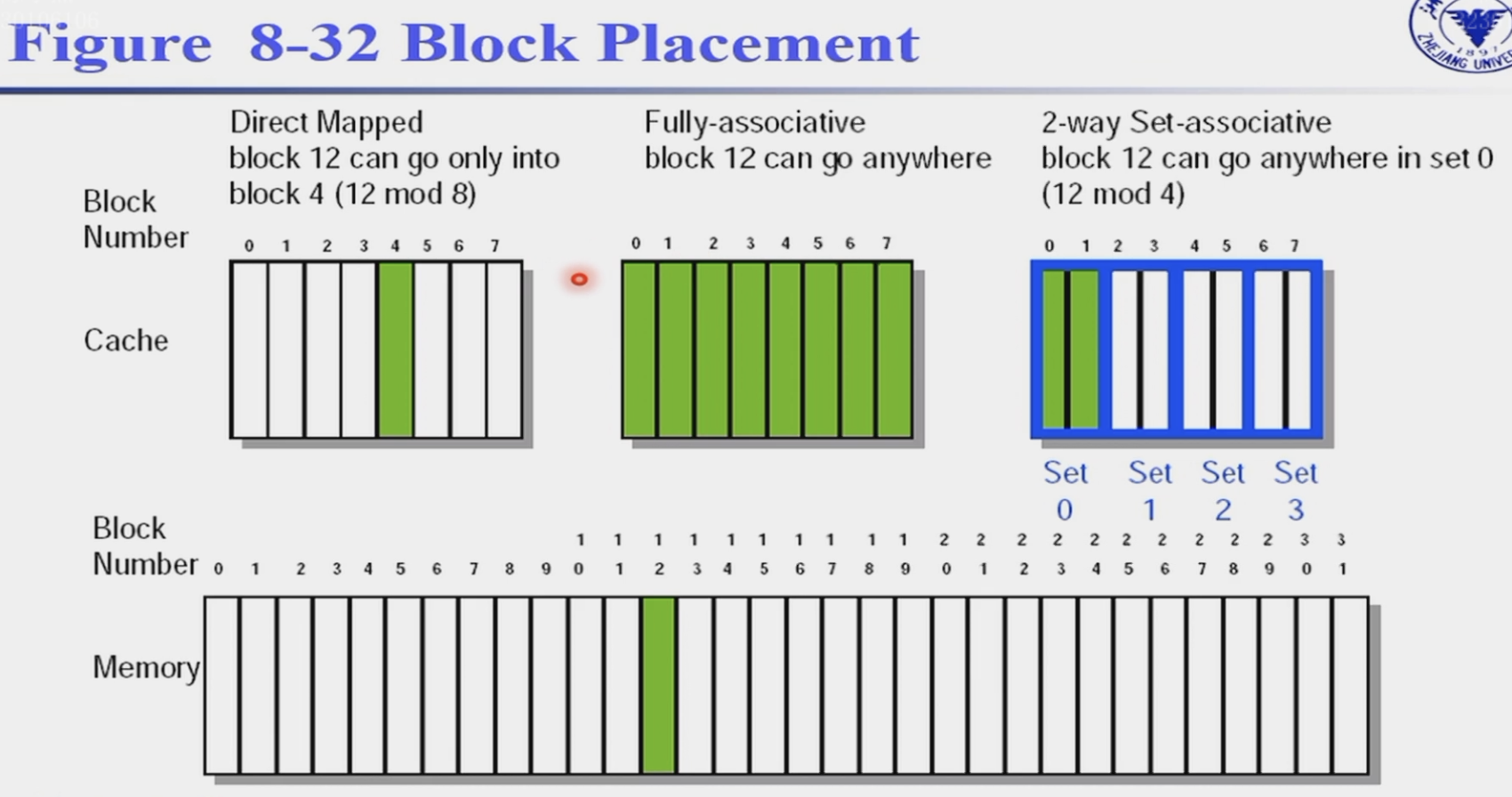
direct map
-
fully associative 全关联
一个数据块可以放在高速缓存的任意位置上
-
set associative 组关联
\[\text{Set Number = (Block number) modulo (Number of sets in the cache)}\]-
这样去到一个set中,然后再选择set中的block,往往是相连的block
-
如果一个set中有n个block,那么就称为n-way set associative(direct map就是1-way set associative)
-
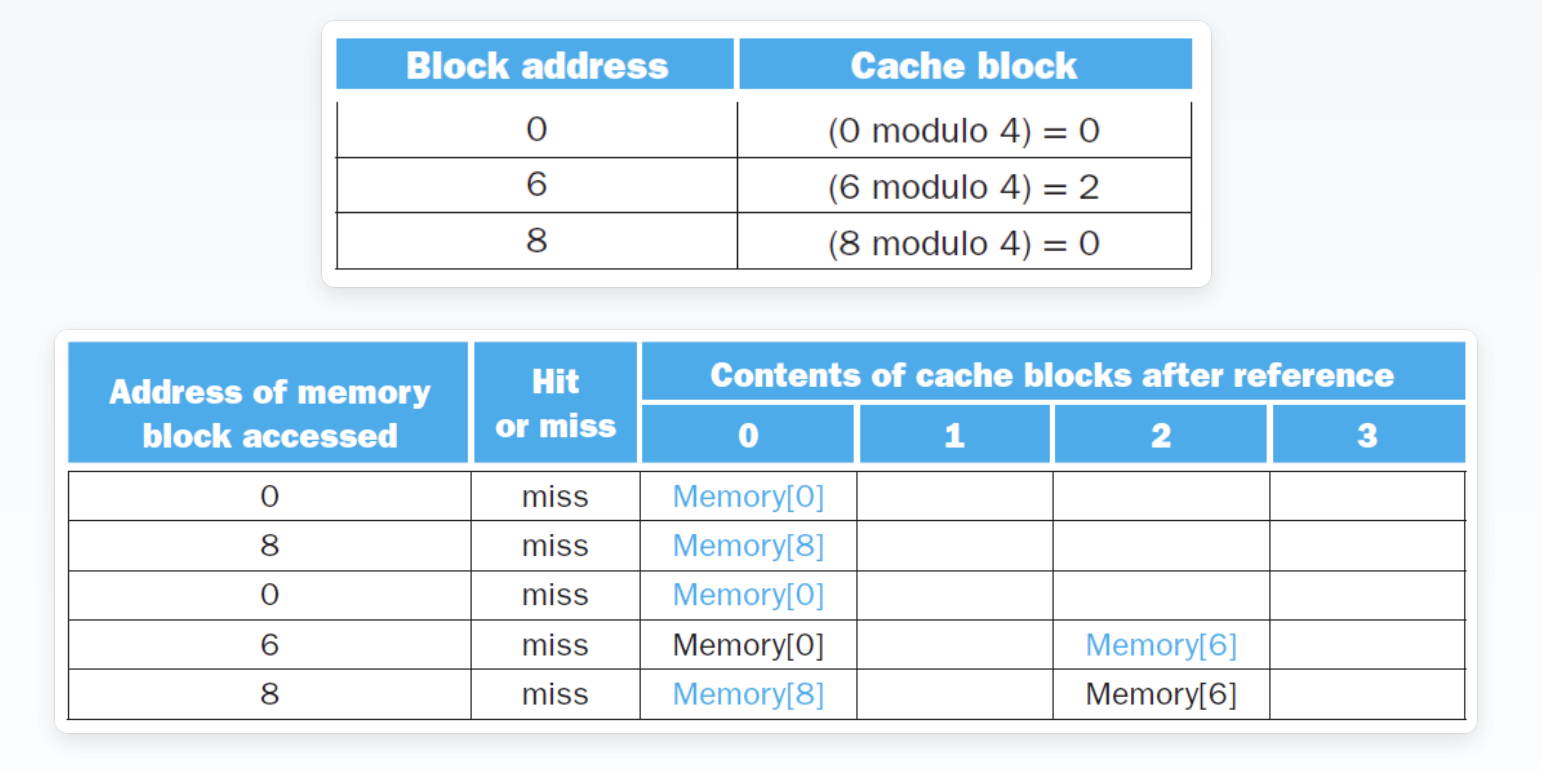
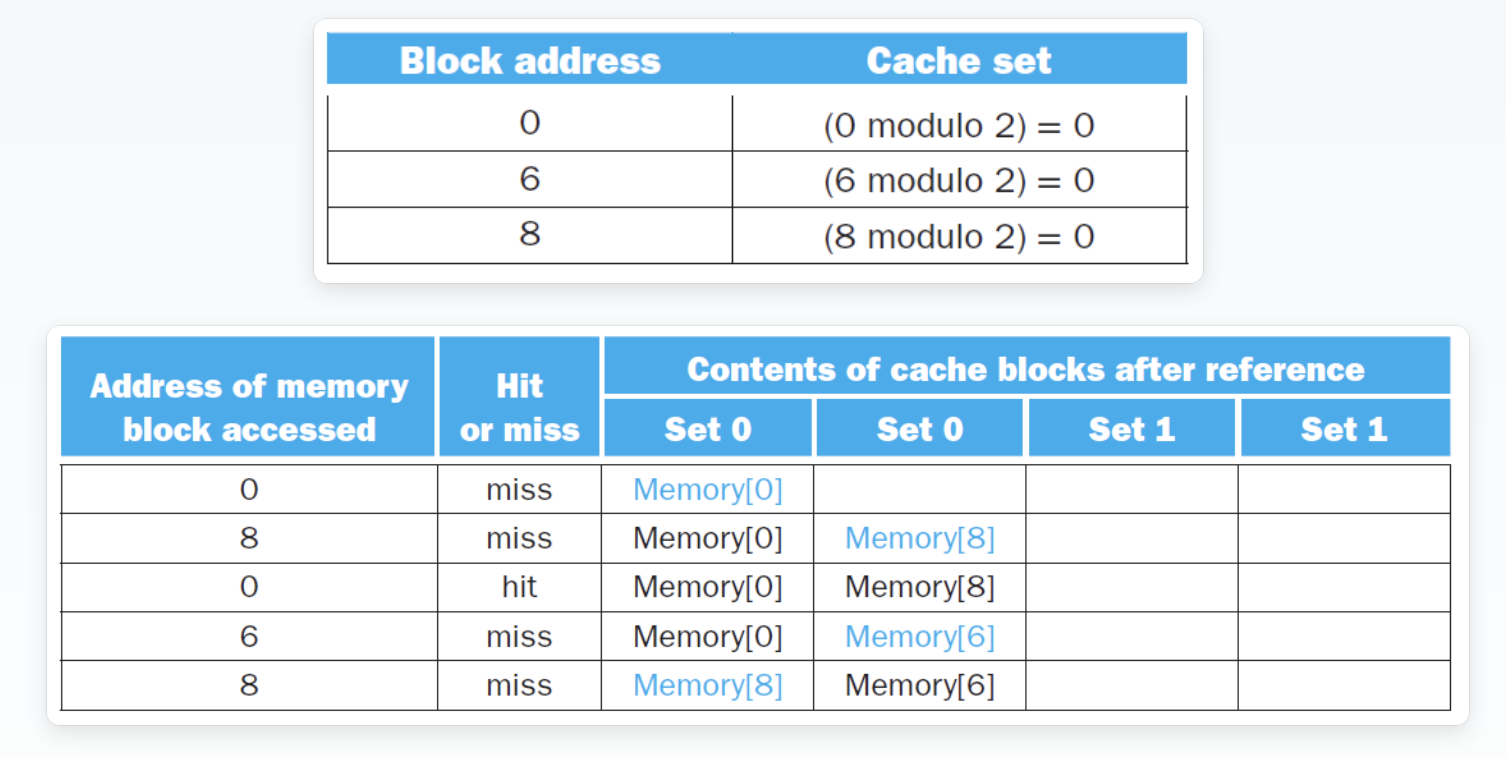
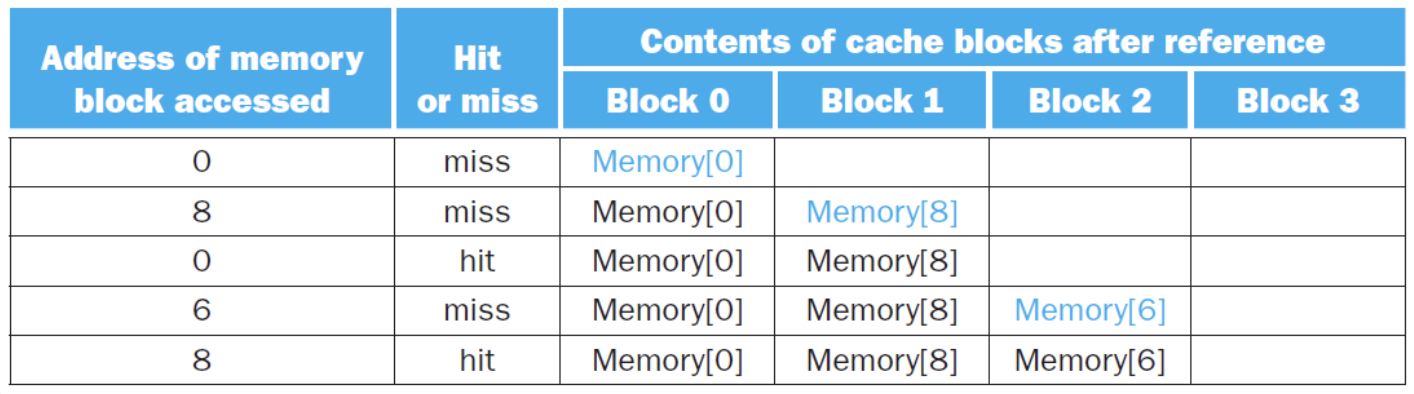
例子
miss次数的比较
题目要求是在一个4-block的cache中分别使用direct map、2-way set associative、fully associative三种方式,计算出miss的次数
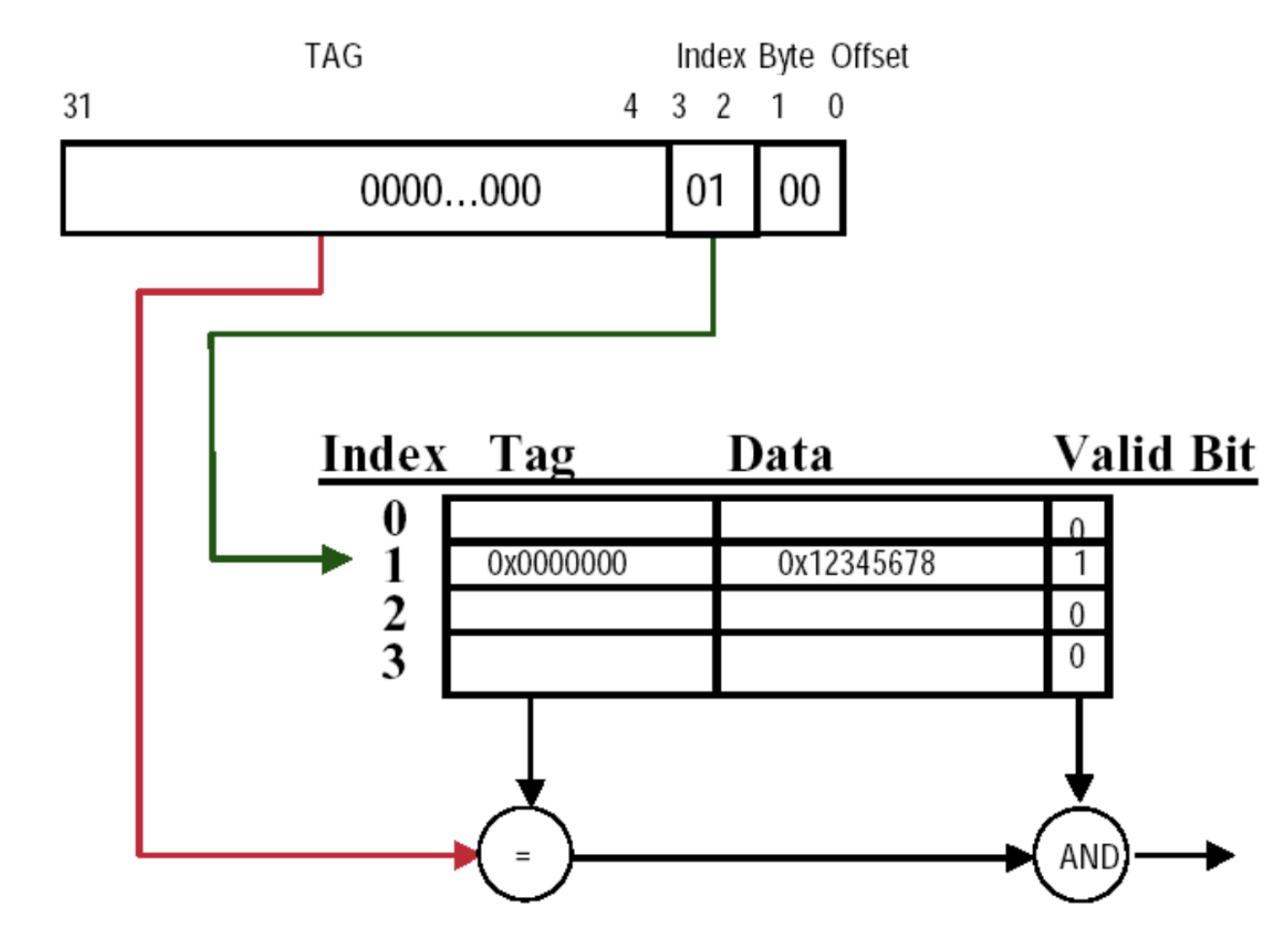
Block Identification¶
虽然方式发生了变化,但是我们仍然采用相同的计算模式:用index、tag、ValidBit、ByteOffset来计算
对于 Physical Address:
-
Index:
- 直接映射:是相对于多少个block来说,位宽:\(\log_2(\text{# blocks})\)
- 组关联:是相对于多少个set来说,位宽:\(\log_2(\text{# blocks in one set})\)
-
Byte Offset:
前面已经给出了
-
Tag:
直接用物理地址减去index和offset即可
compare
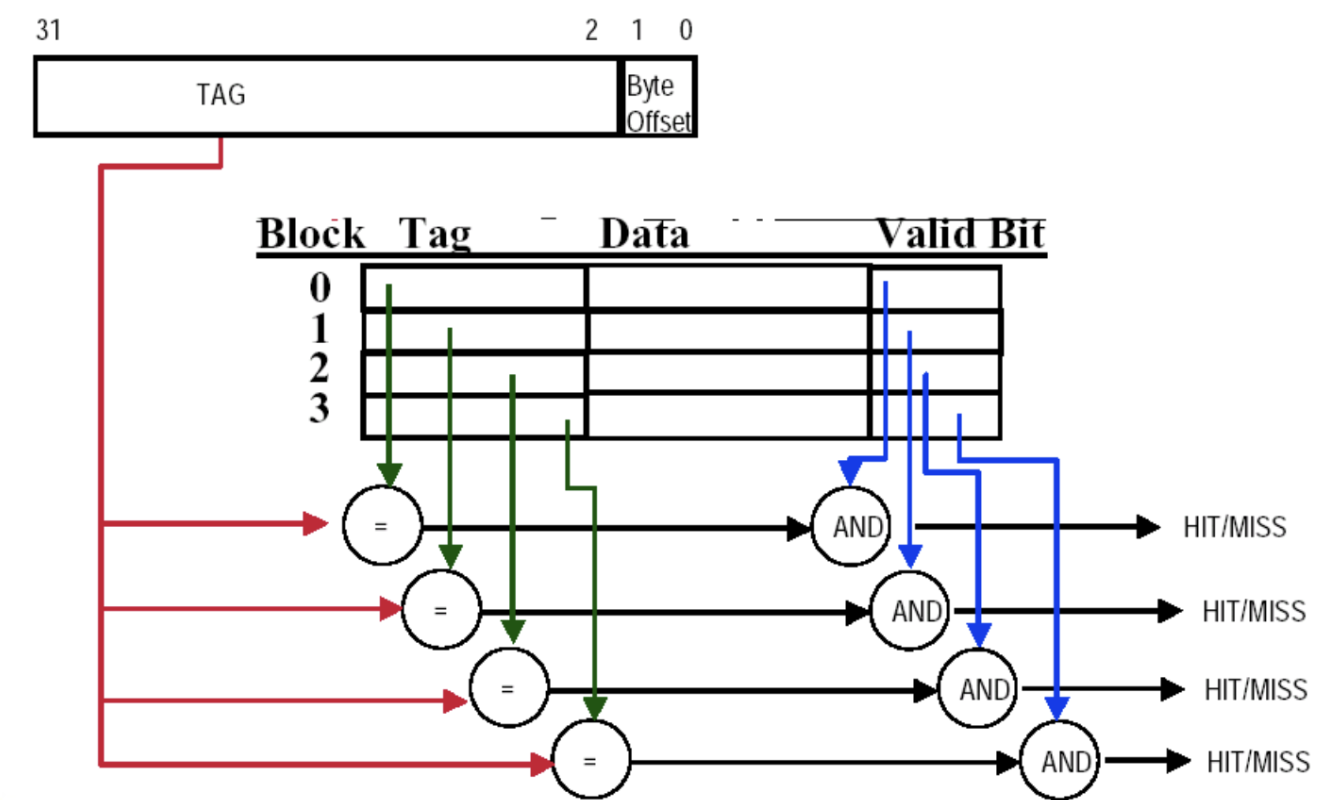
暴力搜索
分成了两组,因此index = 1位,在这个图片中,比较tag发生在所有block中,但其实只需在所选的set中比较即可(图是错的)
Block Replacement¶
- direct map:没有什么替换策略,来了新的就把老的扔了
但是非直接映射中,我们定位不到精确的block,因此在一个set中,我们需要一个策略来决定替换哪一个block
Goal:提高命中率
-
Random Replacement 随机替换
容易实现
-
Least Recently Used (LRU) 最近最少使用
最近没有被用过的踢出
并不是很好实现,尤其是set中有很多block的时候
需要额外的bits来记录每个block的LRU状态
-
First In First Out (FIFO) 先进先出
类似于队列,定一个时间戳
Write Strategy¶
-
Write through
直接将数据写入memory,可以随时把cache中的数据丢掉
只需要Valid bit一位
-
Write back
将数据写入cache,之后再写入memory
需要Valid bit和Dirty bit
好处是memory的带宽可以降低,因为可以减少写入的次数
如果不命中呢?
需要处理Write Stall
-
Write Buffer
相当于一个小的cache,可以暂时存储数据
Write Miss后:
-
Write Allocate
将数据从memory中读到cache中
-
Write Around
不将数据从memory中读到cache中,直接写入memory
通常情况下,Write through 采用Write Around,而Write back采用Write Allocate
Memory Organization¶
对于每次访问操作,我们是要进行block为单位的访问,但是往往有时候我们的block很大,我们需要的word只是block中很小的一部分,这时搬运block就会很浪费时间,因此在这里我们要降低block搬运的时间,尽量做到与word搬运时间差不多
这时候会对memory进行调整,设计出不同的memory organization
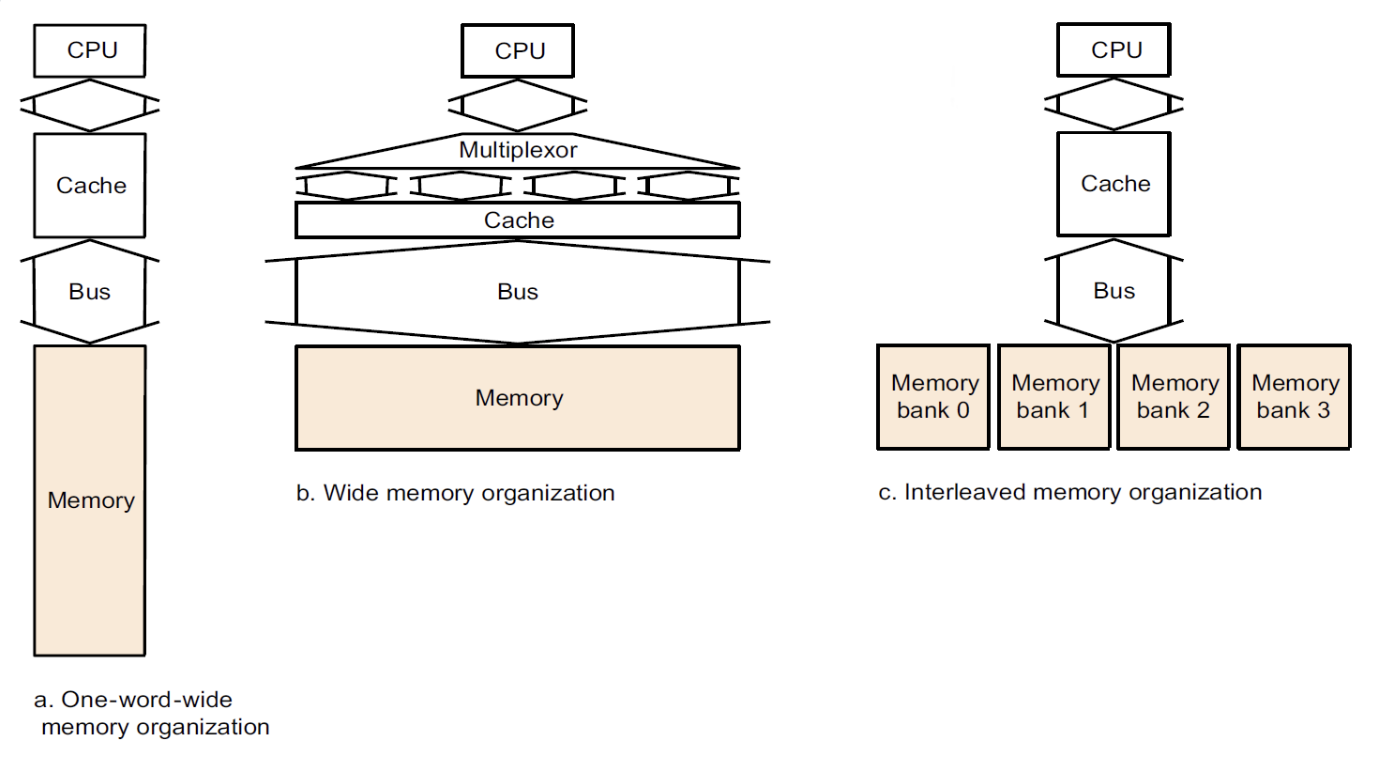

增大width,一次可以读两个word,送回还是一个word,这样可以对读取次数减半
甚至可以增大到4个word,但是这样就miss penalty就很大了

用四个时钟将地址分别传给四个分块的memory,然后进行读取,这样并行的读取后,等待时间就被压缩了
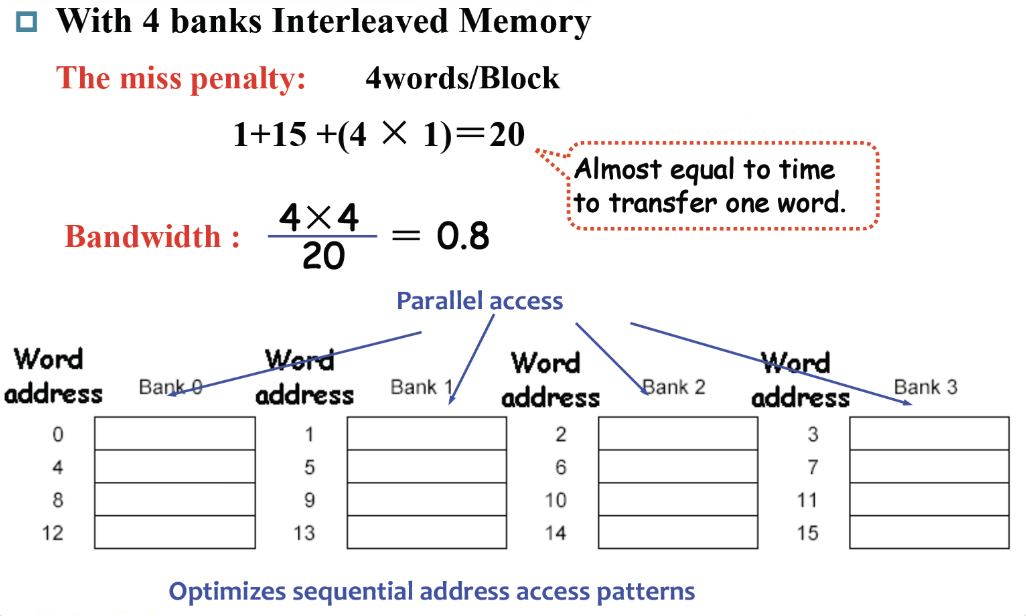
Measure Cache Performance¶
核心问题
怎样测量cache的性能?
如何提高性能?
用CPU的执行时间来衡量cache的性能:
-
Read:取指令+取数据
-
Write:不仅是Program中的Write部分会出现stall,Write buffer也会出现stall
- 如果write buffer很小,可以忽略不计
- 如果cache block size是一个word,那么miss penalty是0
-
通常write-through策略下,读和写的miss penalty是相同的
例子

所以加上penalty后的CPI就是2+3.44=5.44,与理想的CPI=2相比,比例是2.72
如果我们只对处理器优化,不优化内存结构,反而会增大这个比例:

Performance Improvement¶
提高性能的思路只有两种:
- 提高命中率
- 减小下一个访问的延时
Multilevel Cache¶
用于减少miss penalty
常用方法是:加入二级缓存
增加一个二级缓存(SRAM):
- 原来的高速缓存为一级高速缓存 (SRAM)
- 如果一级高速缓存失效,且能够在二级高速缓存找到数据,那么失效损失就是访问二级高速缓存的时间了,大大减小miss penalty
- 如果二级高速缓存也找不到数据,那还是得访问主存,此时的失效损失还是很大
一级缓存:专注于最小化命中时间
- 空间更小,缓存块大小也减小,减小了miss penalty
二级缓存:专注于最小化miss penalty
- 空间更大,缓存块大小更大,降低失效率
例子
有一块 CPI 为 1.0,时钟频率为 4GHz 的处理器,访问主存的时间为 100ns,一级高速缓存的每条指令失效率为 2%,如果加上一块访问时间为 5ns,且能将失效率降至 0.5% 的二级高速缓存,处理器将会变得多快?
clock cycle time = 1 / 5GHz = 0.2ns
- miss penalty to main memory = 100ns/0.2ns = 500
-
一级缓存:
- Total CPI = 1 + 2% * 500 = 11
-
二级缓存:
- 二级miss penalty = 5ns/0.2ns = 25
- Total CPI = 1 + 2% * 25 + 0.5% * 500 = 1 + 0.5 + 2.5 = 4
faster by 11/4 = 2.75 times
Virtual Memory¶
是对main memory而言的,主要解决的是size问题
- 让每个程序都以为自己的内存是独有的,并且足够大
- 让程序觉得自己的内存是连续的
虚拟存储的本质其实与cache类似。它自动地管理主存与辅助存储之间的映射关系,只是名称不同:我们称虚拟空间中的一个存储块称为页(virtual page),
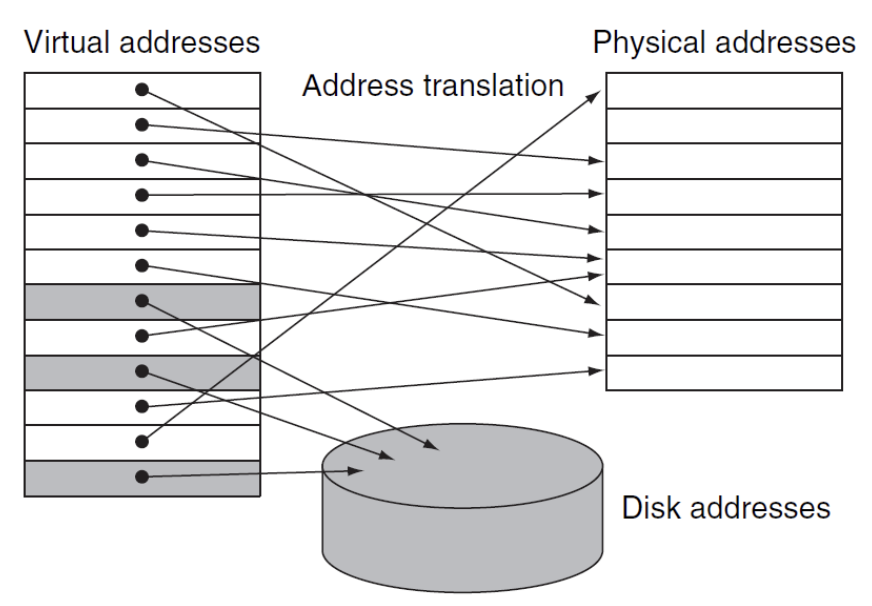
-
虚拟空间(virtual address space):一块单独的内存地址范围,只能被特定的一个程序使用
-
虚拟地址(virtual address):关联虚拟空间位置的地址,会被转译为物理地址
- 可以看到虚拟地址的指向空间并不连续,并且还会有重复地址、指向Disk的情况
-
地址转译(address translation):将虚拟地址转译为物理地址的过程
-
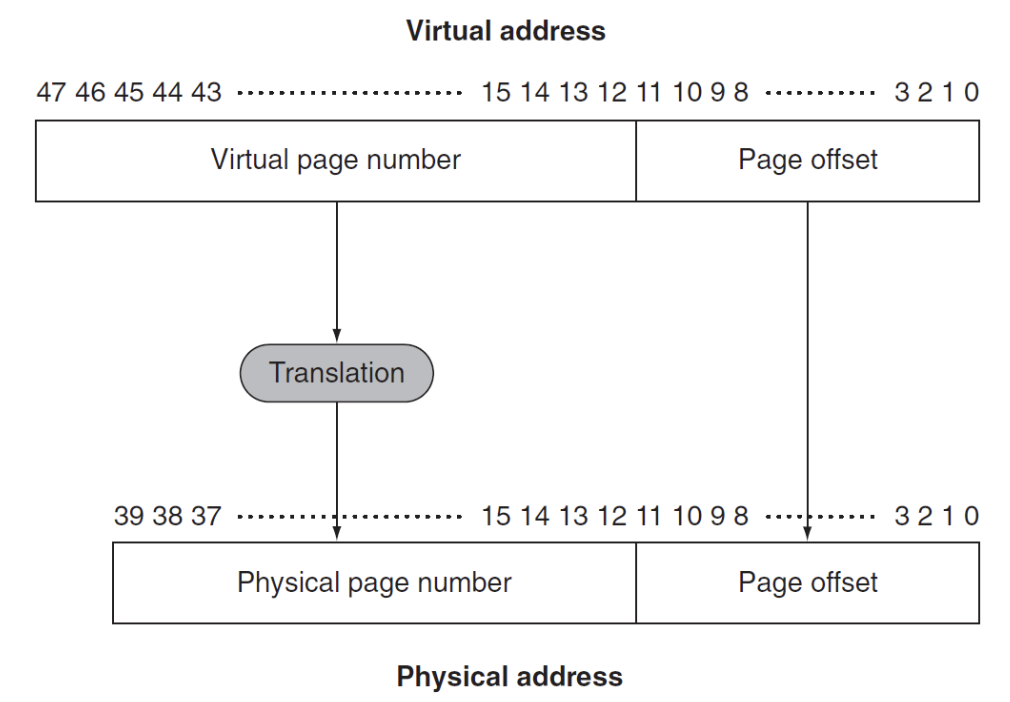
-
一个存储块--页的构成由两部分组成:
在RISC-V中,64位地址的高16位不使用,因此需要映射的地址有48位
- 页号(page number):虚拟地址的一部分,用于索引,指向物理地址,
- 页偏移(page offset):虚拟地址的一部分,用于索引页内的字节,页偏移的大小决定了页的大小
size of page table
一个32bits的虚拟地址,page size = 4KB,Entry size = 4 bytes,至少要多大的page table?
- 32位的虚拟地址可以寻址\(2^{32}\)个字节的内存
- 每个page的大小是4KB,因此需要\(2^{32} / 4KB = 2^{32-12} = 2^{20}\)个page
- 每个page的entry size是4 bytes,因此需要\(2^{20} * 4B = 2^{22}B = 2^{12}KB = 4MB\)的内存来存储page table
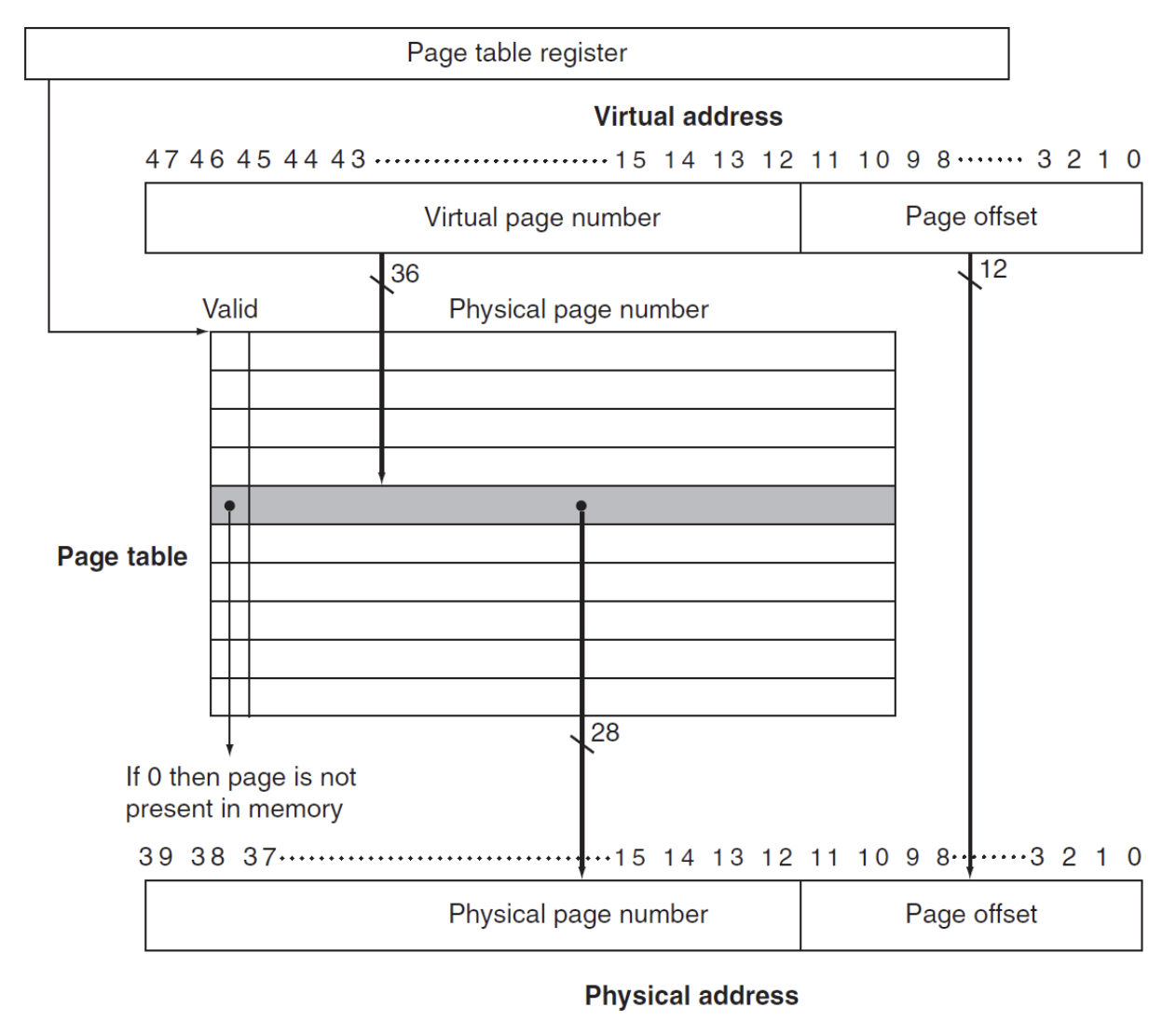
整个虚拟内存的空间都是储存在memory中的
- Page Table:页表,用于存储虚拟地址与物理地址的映射关系
- Page Table register:页表寄存器,用于存储页表的基地址
映射过程就是:
- 当一个程序开始运行,我们读取到他对应的Page table register,然后通过虚拟地址的页号找到对应的物理地址,如果物理地址的Valid bit = 1,说明这个内存块是在memory中的,那么我们就可以直接访问这个内存块
如果这个Valid bit = 0,说明这个内存块在Disk中,这时就发生了page fault
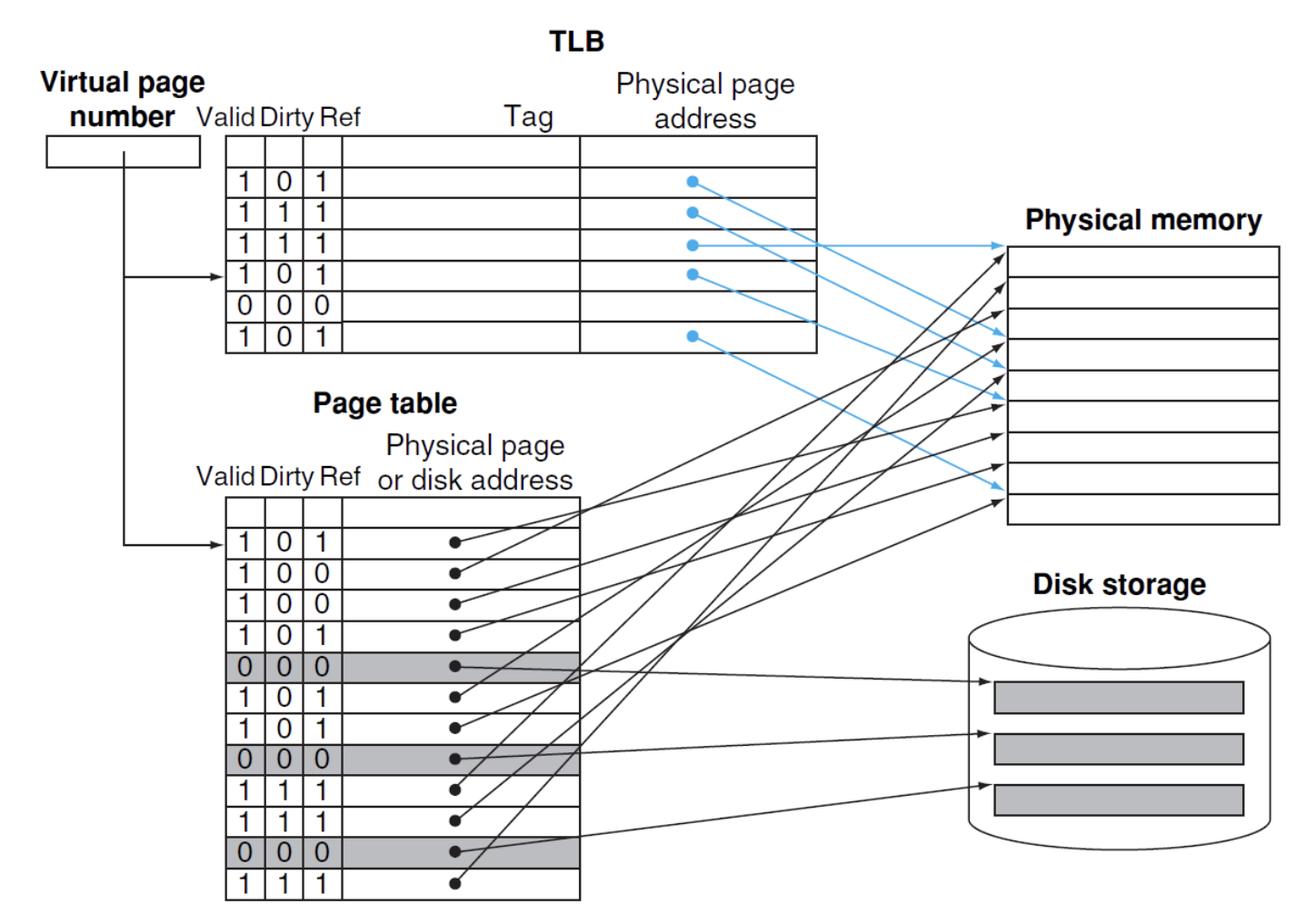
TLB¶
TLB:Translation Lookaside Buffer,增加一个buffer用于追踪最近使用过的地址映射,直接保存物理地址
留言